|
|
You are here: Foswiki>Main/Cimec Web>ProcessorPerformance (20 Sep 2014, MarioStorti)Edit Attach
Algunos detalles sobre la performance de procesadores Pentium 3 y 4 y la memoria Rambus
-- MarioStorti - 19 Apr 2002Recientemente hemos comprado 2 Pentium IV 1.4Ghz con memoria Rambus. Previamente habiamos detectado que el linpack 1000 x 1000 daba una relacion de performance de 4 a 1 o mas en favor del Pentium IV con relacion al Pentium III. (160 Mflops contra 10 Mflops). Pero al correr PETSc-FEM detectamos que en el ensamblaje de la matriz se obtiene en realidad una relacion de 2 a 1 en favor del Pentium III. La idea es centralizar en esta pagina toda la informacion que tengamos (diferentes programas, propios o externos) y opiniones a fin de tomar una decision en cuanto a que procesadores comprar de aqui en mas.
Cpu-rate
Este es un test escrito por Robert Brown ( http://www.phy.duke.edu/brahma/ ) y que esta en Geronimo en/u/mstorti/PETSC/LINPACK_BENCHMARK/cpu-rate-0.0.4 Hace las 4 operaciones *,/,-,+ sobre un vector de tamano variable en doble precision. El resultado es presentado en Bogo-Megadops . La "d" viene de double y el bogo viene de bogus (falso).
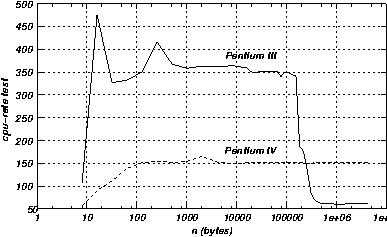
Cpu-rate performance curve for P3 and P4 processor
Este test indica que para grandes tamanos del vector, el P4 es hasta cuatro mas de dos veces mas rapido que el P3. Sin embargo para tamanos pequenos la relacion se invierte, el P4 es 2.3 veces mas lento. El punto de corte se produce bruscamente, cuando el tamanho del vector pasa a ser mas grande que el cache del procesador (256Kbytes).
Linpack dinamico
Los linpack tiran los siguientes numeros| Linpack size | Pentium 3-866Mhz | Pentium 4-1.4Ghz |
| 100x100 [Mflops] | 152 | 305 |
| 1000x1000 [Mflops] | 39 | 231 |
n en todo un rango (por ejemplo desde 20 hasta 1000) y obtuvimos la siguiente curva. (ver codigo fuente en DynamicLinpack )
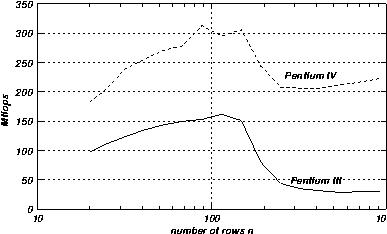
Linpack dynamic test
Notar la bajada en performance en ambos casos para n cerca de 180 que corresponde approx. al tamano del cache (
8*180^2 approx 256k). Fijense que curiosamente el cpu-rate no da una bajada en performance para el P4 cuando los datos se salen del cache.
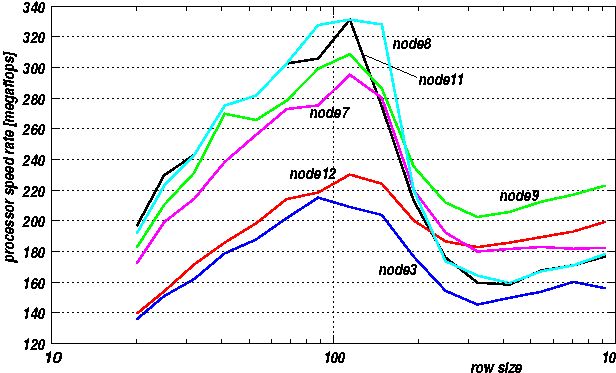
Otro test con Linpack en procesadores P, P3 y Athlon: http://www.tech-report.com/reviews/2001q3/piii-1.2/index.x?pg=5 A continuacion incluimos la figura del test:
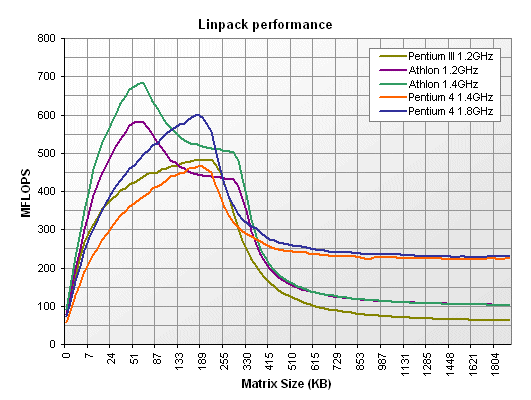 -- MarioStorti - 17 Nov 2002
-- MarioStorti - 17 Nov 2002
Conclusiones
No es claro cual procesador conviene. Invito a todos aquellos que tengan algun test a que envien resultados para que todos podamos comparar y tomar una decision. Sobre todo tengan en cuenta que es conveniente que el test sea dinamico, es decir que cubra un rango de tamanos del problema, ya que por lo visto el comportamiento puede ser muy diferente en un regimen que en otro.Prueba con diferentes librerias BLAS. Linpack dinamico
-- MarioStorti - 31 May 2002Corrimos el dyntest (ver DynamicLinpack) en
astroboy con las librerias blas y lapack que vienen con Red Hat (probablemente compiladas con GCC/G77) y la provista por Intel. (librerias MKL). El resultado es ligeramente mejor para las estandar.
| n | MKL Library [Mflops] | Red Hat standard libs [Mflops] |
| 20 | 143.3 | 141.9 |
| 25 | 171.6 | 173.6 |
| 32 | 211.3 | 214.4 |
| 41 | 246.6 | 250.9 |
| 53 | 287.4 | 287.4 |
| 68 | 302.6 | 309.3 |
| 88 | 312.8 | 320.1 |
| 114 | 367.1 | 377.3 |
| 148 | 274.4 | 298.8 |
| 192 | 110.8 | 116.6 |
| 249 | 59.80 | 60.3 |
| 323 | 41.37 | 43.2 |
| 419 | 35.58 | 36.3 |
| 544 | 33.55 | 34.1 |
| 707 | 32.57 | 33.2 |
| 919 | 32.02 | 32.9 |
Test del Juego de la Vida
-- MarioStorti - 3 May 2002El Juego de la Vida ( Game of Life ) consiste en un tablero de
NxN celdas las cuales tienen dos estados ( viva o muerta ). El sistema evoluciona de acuerdo a la siguientes reglas:
- Si una celda tiene exactamente 3 de sus 8 vecinas vivas entonces pasa a estar viva (independientemente de su estado anterior)
- Si tiene dos celdas vivas entonces queda en el estado anterior
- En cualquier otro caso (numero de celdas vecinas vivas = 0,1, 4, 5, 6, 7, 8) la celda muere ( superpoblacion o soledad )
- http://www.math.com/students/wonders/life/life.html
- http://www.mindspring.com/~alanh/life/
- http://dir.yahoo.com/Science/Artificial_Life/Cellular_Automata/Conway_s_Game_of_Life/
-O2 -funroll-loops (ver GameOfLife) obtenemos los siguientes numeros:
| Processor | rate [Mcells/secs] |
| Pentium 3 500Mhz | 18 |
| Pentium 3 866Mhz | 25 |
| Pentium 4 1.4Ghz(AG) | 43 |
| Pentium 4 1.4Ghz(HW) | 53 |
| Pentium 4 1.7Ghz(HW)[node8] | 57.2 |
Juego de la vida
-- MarioStorti - 24 May 2002Incluyendo el nuevo P4 (node3) tenemos el resultado siguiente: %STARTCONSOLE% [mstorti@node1 life]$ bw Enter command: /u/mstorti/PETSC/life/life.bin -N 1000 -s 100 -q
On processor #0 [uname: node1]------- N 1000, steps 100, elapsed 3.662080, rate: 27.306886 Mcell/sec
On processor #1 [uname: node2]------- N 1000, steps 100, elapsed 3.649341, rate: 27.402208 Mcell/sec
On processor #2 [uname: node3]------- N 1000, steps 100, elapsed 2.150364, rate: 46.503755 Mcell/sec
On processor #3 [uname: node4]------- N 1000, steps 100, elapsed 3.649171, rate: 27.403484 Mcell/sec
On processor #4 [uname: node5]------- N 1000, steps 100, elapsed 3.649437, rate: 27.401487 Mcell/sec
On processor #5 [uname: node6]------- N 1000, steps 100, elapsed 3.556003, rate: 28.121461 Mcell/sec
On processor #6 [uname: node7]------- N 1000, steps 100, elapsed 3.649628, rate: 27.400053 Mcell/sec
On processor #7 [uname: node8]------- N 1000, steps 100, elapsed 5.045658, rate: 19.819021 Mcell/sec
On processor #8 [uname: node9]------- N 1000, steps 100, elapsed 1.774409, rate: 56.356793 Mcell/sec
On processor #9 [uname: node10]------- N 1000, steps 100, elapsed 5.046064, rate: 19.817426 Mcell/sec
On processor #10 [uname: node11]------- N 1000, steps 100, elapsed 5.009025, rate: 19.963965 Mcell/sec
On processor #11 [uname: node12]------- N 1000, steps 100, elapsed 2.139536, rate: 46.739106 Mcell/sec [mstorti@node1 life]$ %ENDCONSOLE% Entonces usando un
proctable (ver PetscFEMProcTable) con esos pesos obtenemos:
%STARTCONSOLE%
[mstorti@node1 life]$ make test1
mpirun -machinefile machi.dat -np 12 life.bin -N 4000 -s 2000 -q -w
N 4000, steps 2000, elapsed 94.524566, rate: 338.536334 Mcell/sec
[mstorti@node1 life]$ cat weights.dat
27.30 node1
27.40 node2
46.50 node3
27.40 node4
27.40 node5
28.12 node6
27.40 node7
19.81 node8
56.35 node9
19.81 node10
19.96 node11
46.73 node12
[mstorti@node1 life]$
%ENDCONSOLE%
contra una teorica de la suma de los rate individuales que da 374Mcells/sec lo cual da una eficiencia de 90%.
Evaluacion de elementos con PETSc-FEm
-- MarioStorti - 07 May 2002Aparentemente la perdida de performance con el P4 en la parte de evaluacion de elementos de PETSc-FEM era algo asociado a la sincronizacion/paralelismo. Corriendo el programa en secuencial en cada una de las maquinas da lo siguiente. Evaluacion de jacobiano y residuo con optimizacion
-O2 -funroll-loops , con PETSC-FEM beta-2.94.pl12, se evaluan 3456 elementos en chunks de 1000
| Processor | "raw" rate [secs/Ke] | averg. rate [secs/Ke] | elapsed [secs] |
| Pentium 4-1.4GHz (node12) | 2.7 | 3.8 | 15.2 |
| Pentium 3-866MHz (node1) | 9.2 | 10.4 | 38.4 |
| Pentium 3-500MHz (node8) | 10.2 | 12.2 | 45.9 |
nsi_keps_rot compilado con -O2-funroll-loops , version beta-2.94.pl18
| Processor | elapsed[secs] | rate [Ke/secs] |
| node (P3) | 30.17 | 0.099 |
| node3 (AG) | 12.56 | 0.239 |
| node9 (HW) | 9.43 | 0.318 |
| node3 (AG) | 10.61 | 0.283 |
Diferencia entre los Pentium IV
-- MarioStorti - 23 May 2002Hemos detectado mucha fluctuacion en las velocidades de los diferentes Pentium IV, entre proveedores y entre los mismos P4 provistos por un proveedor (AG).
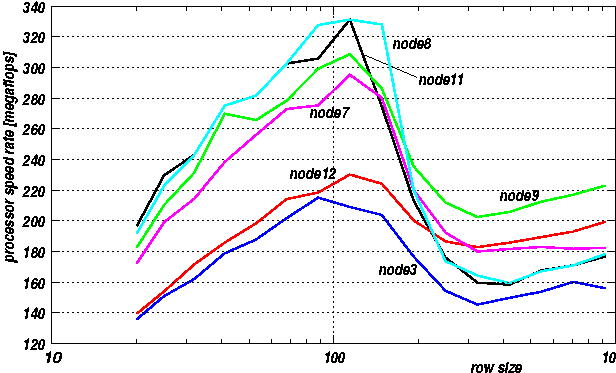
Juego de la vida con Portland Group compiler y GNU g++ (ver PgiCompiler y GameOfLife) para un tablero A (n,n) con n = 1000 y g=500 generaciones. Los "rate" son calculados como
1000x1000x500/T donde T es el tiempo transcurrido en secs y se expresan en [Mcells/sec]. Para cada programa se expresa el tiempo transcurrido en secs, y los "rate" correspondientes en la columna vecina.
Prog1 y prog2 son compilados con PGHPF (ver PgiCompiler). Uno usa HPF y el otro MPI, pero a efectos de este test (que es secuencial) eso solo puede tener una incidencia indirecta. El life.cpp esta en GameOfLife.
| nodes | Prog 1 + PGHPF | Prog 2 + PGHPF | life.cpp + GNU g++ | |||
|---|---|---|---|---|---|---|
| T | rate | T | rate | T | rate | |
| Node3 | 43.45 | 11.5 | 22.31 | 22.4 | 11.6 | 43.3 |
| Node9 | 34.10 | 14.6 | 18.18 | 27.5 | 9.3 | 53.2 |
| Node12 | 37.09 | 13.4 | 21.28 | 23.5 | 11.4 | 43.8 |
Memoria DDR
Performance de una maquina con memoria DDR: Intel P4 1.8GHz, memoria DDR de 333MHz. Corremos el dyntest ( DynamicLinpack ) se ve que tiene un pico para n=114 que esta por arriba de los nodos con 1.7GHz pero Rambus, lo cual esta OK por la velocidad del procesador, pero despues la performance cae a 156MFlops contra 178 pico de la memoria Rambus, lo cual se debe a que la DDR es un poco mas lenta (menos de un 12%). Pero hay que tener en cuenta que la DDR es menos de la mitad de costosa que la RAMBUS. En este momento la DDR cuesta u$s 105 el peine de 512MB/PC-333MHz mientras que la Rambus cuesta u$s 256 el peinde de 156MB/PC-600MHz.| n (row size) | MFlops (dyntest) |
| 20 | 215.96 |
| 25 | 237.03 |
| 32 | 270.03 |
| 41 | 286.09 |
| 53 | 320.08 |
| 68 | 323.72 |
| 88 | 327.74 |
| 114 | 357.45 |
| 148 | 336.26 |
| 192 | 223.64 |
| 249 | 173.60 |
| 323 | 153.20 |
| 419 | 151.50 |
| 544 | 151.57 |
| 707 | 154.23 |
| 919 | 156.83 |


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
cpu_rate.jpg | manage | 25 K | 19 Apr 2002 - 19:28 | UnknownUser | Cpu-rate performance curve for P3 and P4 processor |
| |
dyntest.jpg | manage | 18 K | 19 Apr 2002 - 19:43 | UnknownUser | Linpack dynamic test |
| |
linpack.gif | manage | 29 K | 17 Nov 2002 - 17:59 | UnknownUser | Linpack test |
| |
p4.gif | manage | 8 K | 30 Aug 2002 - 17:00 | UnknownUser | |
| |
p4.jpg | manage | 62 K | 30 Aug 2002 - 16:59 | UnknownUser | dyntest for several P4 |
Edit | Attach | Print version | History: r19 < r18 < r17 < r16 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r19 - 20 Sep 2014, MarioStorti
Main/Cimec Web
Cursos de grado y posgrado
Navegación

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cursos de grado y posgrado
- Algoritmos y Estructuras de Datos
- Cálculo Numérico
- Cálculo Paralelo
- CFD
- HPC en MC
- Cálculo Tensorial en Mec. del Cont.
- Computación Gráfica
- Programación en C++ para Ciencia e Ingeniería
- Introducción al MEF
- Mecánica del Continuo
- Mecánica Computacional
- Mecánica de Fluidos
- Mecánica de Sólidos
- Mecánica Racional
- Métodos Iterativos
- Teoría de la Computación
Navegación
Ideas, requests, problems regarding Foswiki? Send feedback